Cover tree
The cover tree is a type of data structure in computer science that is specifically designed to facilitate the speed-up of a nearest neighbor search. It is a refinement of the Navigating Net data structure, and related to a variety of other data structures developed for indexing intrinsically low-dimensional data.[1]
The tree can be thought of as a hierarchy of levels with the top level containing the root point and the bottom level containing every point in the metric space. Each level C is associated with an integer value i that decrements by one as the tree is descended. Each level C in the cover tree has three important properties:
- Nesting:
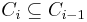
- Covering: For every point
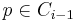 , there exists a point
, there exists a point 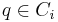 such that the distance from
such that the distance from 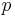 to
to 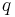 is less than or equal to
is less than or equal to 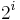 and exactly one such is a parent of .
and exactly one such is a parent of . - Separation: For all points
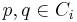 , the distance from to is greater than .
, the distance from to is greater than .
Contents |
Complexity
Find
Like other metric trees the cover tree allows for nearest neighbor searches in 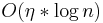 where
where 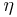 is a constant associated with the dimensionality of the dataset and n is the cardinality. To compare, a basic linear search requires
is a constant associated with the dimensionality of the dataset and n is the cardinality. To compare, a basic linear search requires 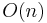 , which is a much worse dependence on
, which is a much worse dependence on  . However, in high-dimensional metric spaces the constant is non-trivial, which means it cannot be ignored in complexity analysis. Unlike other metric trees, the cover tree has a theoretical bound on its constant that is based on the dataset's expansion constant or doubling constant (in the case of approximate NN retrieval). The bound on search time is
. However, in high-dimensional metric spaces the constant is non-trivial, which means it cannot be ignored in complexity analysis. Unlike other metric trees, the cover tree has a theoretical bound on its constant that is based on the dataset's expansion constant or doubling constant (in the case of approximate NN retrieval). The bound on search time is 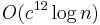 where
where 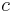 is the expansion constant of the dataset.
is the expansion constant of the dataset.
Insert
Although cover trees provide faster searches than the naive approach, this advantage must be weighed with the additional cost of maintaining the data structure. In a naive approach adding a new point to the dataset is trivial because order does not need to be preserved, but in a cover tree it can take 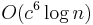 time. However, this is an upper-bound, and some techniques have been implemented that seem to improve the performance in practice.[2]
time. However, this is an upper-bound, and some techniques have been implemented that seem to improve the performance in practice.[2]
Space
The cover tree uses implicit representation to keep track of repeated points. Thus, it only requires O(n) space.
See also
References
- ^ Kenneth Clarkson. Nearest-neighbor searching and metric space dimensions. In G. Shakhnarovich, T. Darrell, and P. Indyk, editors, Nearest-Neighbor Methods for Learning and Vision: Theory and Practice, pages 15--59. MIT Press, 2006.
- ^ http://hunch.net/~jl/projects/cover_tree/cover_tree.html
- Alina Beygelzimer, Sham Kakade, and John Langford. Cover Trees for Nearest Neighbor. In Proc. International Conference on Machine Learning (ICML), 2006.
- JL's Cover Tree page. John Langford's page links to papers and code.
- A C++ Cover Tree implementation on GitHub.
|
||||||||||||||||||||||||||